RegEx 101 (Working With Text 2)
Let’s say that there was a revolution in your field site and the “Feline Republic” is now the “Canine Republic.” This is an easy problem to solve. You just open up your word processor and use the find and replace command, replacing every instance of “Feline” with “Canine.” But what if the canine revolution also imposed new rules for personal names, reversing the order of first and last names throughout the republic? That becomes a bit more difficult. If your article includes hundreds of names, it would take at least an hour of manual labor to find and fix each name in your paper. In today’s post, I want to show you how you can save some time by using tools possibly already available in your word processor1 to do a much more advanced search and replace operation.
What we will do is look for every instance in your text of two words in a row that are both capitalized and then reverse the order of those two words. While this scenario may seem somewhat far-fetched, the technique we will use to solve the problem, using Regular Expressions (RegEx), is one of the most useful things I ever learned in my life. I use RegEx several times a month to solve all kinds of problems. You may find it a little frustrating to use the first time, but once you get the hang of it, and discover some tools to help you get the code just right, it will become a regular part of your toolkit. Examples of things I use RegEx for include cleaning up extraneous line breaks in text copied from a PDF, extracting information (like email addresses) from a large text file, or combining cells imported from a database into a properly formatted document. The uses are endless, and once you know how to do it you might find yourself thinking “If I spend 10 min figuring out the correct RegEx for this I can save myself hours of work.”2
Let’s start by grabbing a sample text to use for the tutorial. I’ve copied the following from the intro to the latest issue of Cultural Anthropology, which is useful because it has a bunch of names, but also poses some unique challenges:
The year’s final issue of Cultural Anthropology features a new contribution to our Openings and Retrospectives section, an Openings collection on “Chemo-Ethnography.” Nicholas Shapiro and Eben Kirksey make the case for a critical engagement with modern chemistry in its political, economic, and affective valences, inviting us to take “chemo” seriously as that which can both cure and poison. In her essay, Michelle Murphy evaluates technoscientific practices that have come to materialize chemical exposure, indicating how infrastructures of chemical violence are cloaked even as the violent effects of exposure invite surveillance and pathologization of those living in hostile conditions. Elizabeth Povinelli’s piece inhabits a chemical burn from the inside, meditating on intoxication and exposure; fire and fog; invisibility, velocity, and the training of neural noticings.
Since we now live in the Canine Republic, “Nicholas Shapiro” needs to be written as “Shapiro Nicholas,” but “Cultural Anthropology” should not be re-written. Also, we will run into a problem with the fact that Elizabeth Povinelli’s name is written with the possessive “’s”. Let’s take these problems one by one.
First, we have to find the proper names in this paragraph. To do that I will start with the simplest definition of what a proper name should look like: a word that starts with a capital letter and is followed by a number of lower case letters and then a space. This is what that looks like in RegEx: [A-Z][a-z]+\s Let’s break that down:
-
[A-Z]looks for any capital letters -
[a-z]looks for any lower case letters -
+extends the search for lowercase letters by saying we can have one or more matching results for the previous search parameter (i.e. “a” or “aa” or “aaaaaa”) -
\slooks for a space
This is what that gets us (click on any of the images in this post to go to the RegEx101 site where you can play around with the code to see how it changes the results):
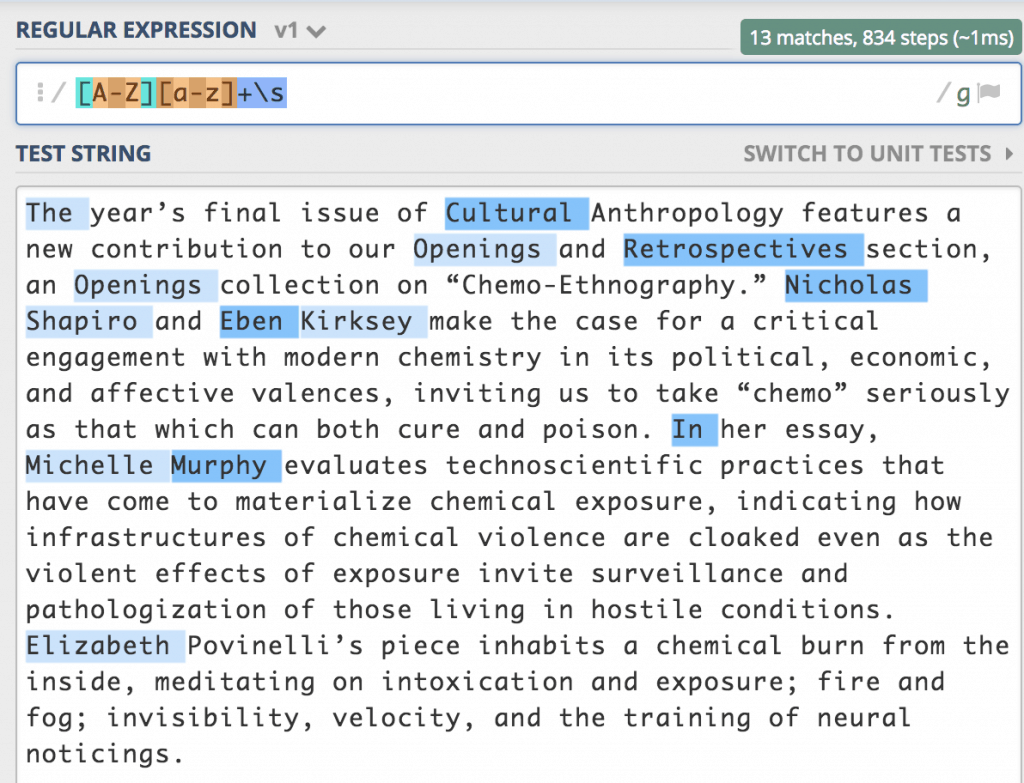
As you can see, this search result catches too many fish in its net. We want to catch the big fish, but leave the small fish (like “The”) out. The easiest way to do this is to replicate the search so that we only find cases where two proper names appear in a row. Like this: [A-Z][a-z]+\s[A-Z][a-z]+\s
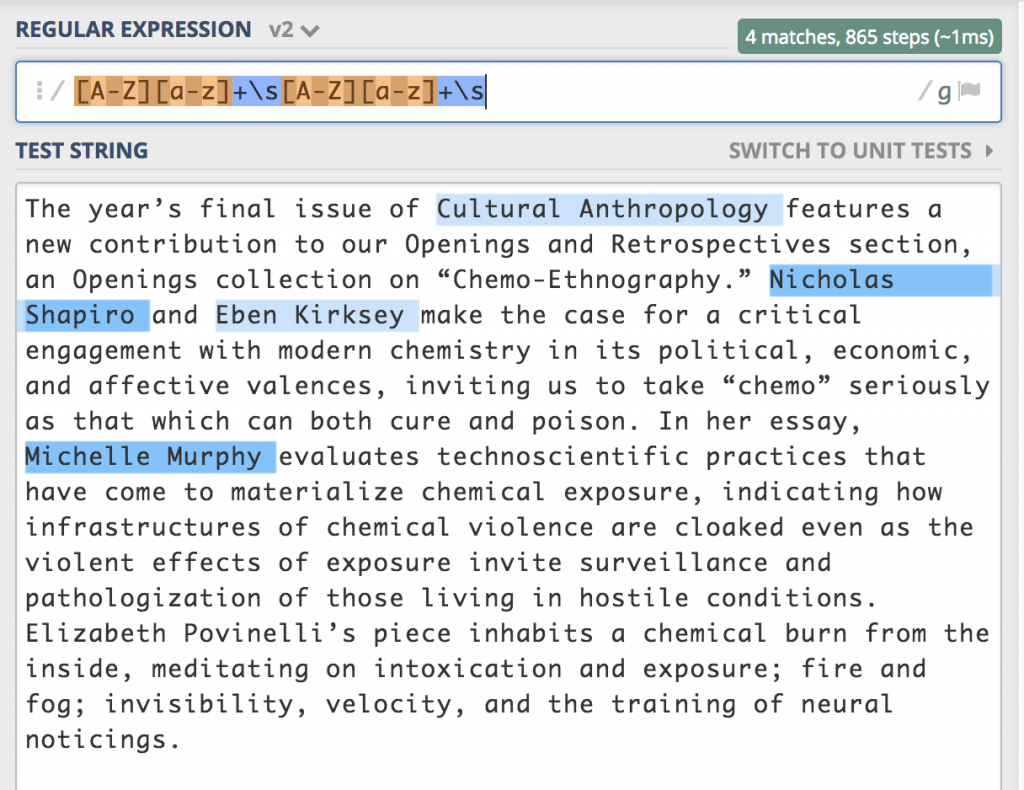
But now we have one catch that isn’t a fish: “Cultural Anthropology” and one fish that got away: “Elizabeth Povinelli.” We can easily tell the search to ignore names starting with “Cultural” by adding (?!Cultural) to the start of the search. But why didn’t Elizabeth Povinelli come through? It was excluded because of the possessive apostrophe, so we can add the apostrophe to the list of characters we search for in the second name. Now our search looks like this: (?!Cultural)[A-Z][a-z]+\s[A-Z][a-z’]+\s
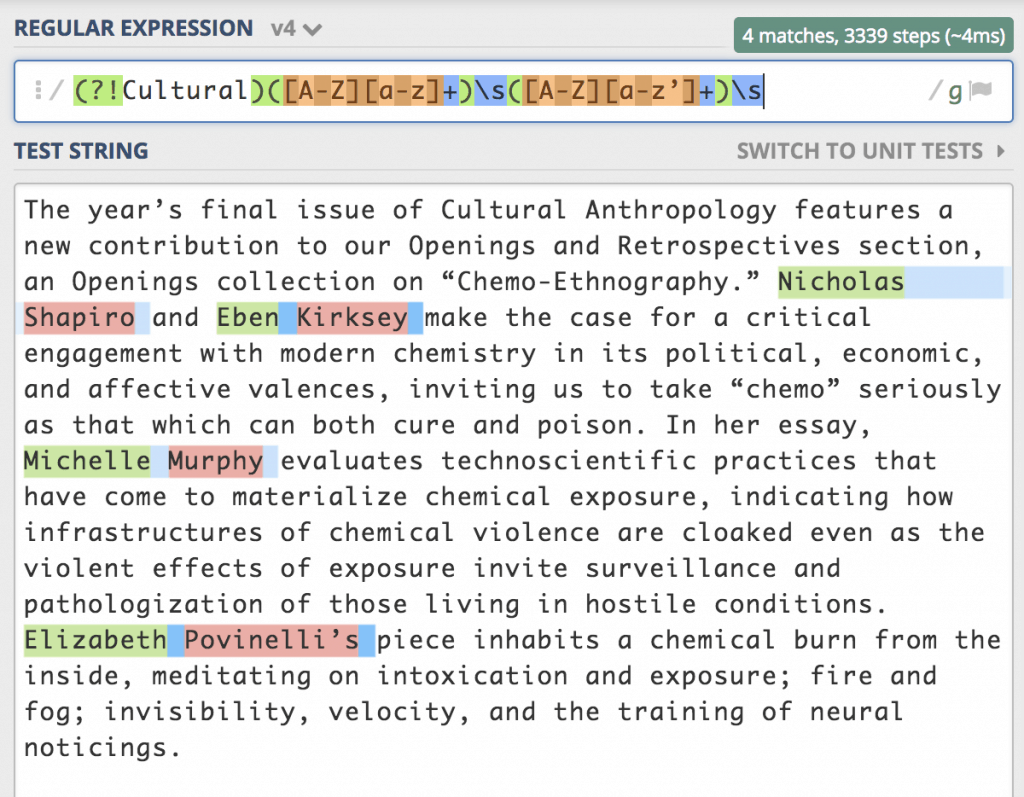
So far, so good. We have caught all the fish we wanted, and only those fish. One problem with RegEx is that it is rare that you can find a search that will work for every single use case. That is why some websites might reject your email address as invalid even though it isn’t. (Actually, a good RegEx should really work with almost all email addresses, but some programmers are just lazy.) For this reason, it is good to write new search parameters for each search you do and to test them against the document you are working on before using them. RegEx is powerful, but that very power can wreak havoc on your text if you aren’t careful!
So far we have only solved the first part of the problem. Once we have found the proper names, we need to reverse their order. To do that we have to mark off the first word and the second word with parentheses in our search, as such: (?!Cultural)([A-Z][a-z]+)\s([A-Z][a-z’]+)\s Our search hasn’t changed, but we can now use those bracketed results in our replace command, which will look like this: \2 \1 That tells the program to write out the second search result, followed by a space and then the first search result, followed by another space. This is almost perfect, except for one small problem you may have already guessed:
The year’s final issue of Cultural Anthropology features a new contribution to our Openings and Retrospectives section, an Openings collection on “Chemo-Ethnography.” Shapiro Nicholas and Kirksey Eben make the case for a critical engagement with modern chemistry in its political, economic, and affective valences, inviting us to take “chemo” seriously as that which can both cure and poison. In her essay, Murphy Michelle evaluates technoscientific practices that have come to materialize chemical exposure, indicating how infrastructures of chemical violence are cloaked even as the violent effects of exposure invite surveillance and pathologization of those living in hostile conditions.
Povinelli’s Elizabethpiece inhabits a chemical burn from the inside, meditating on intoxication and exposure; fire and fog; invisibility, velocity, and the training of neural noticings.
Unfortunately, we ended up with “Povinelli’s Elizabeth” instead of “Povinelli Elizabeth’s” which is what our canine overlords wanted. Rather than changing our original search and replace to avoid this problem, it is easier to follow the first search and replace operation with another one that will clean up these mistakes. In this case the search command would look like ([A-Z][a-z]+)’s\s([A-Z][a-z]+)\s and the replace command would be \1 \2's . At this point you should be able to understand how this works. Take a moment to see if you can understand the code before moving on.
Obviously, it would never make sense to write code to fix a single instance in a document, it would be easier to do it by hand, but if you had a 20-page paper to work with, not to mention a book manuscript, you might appreciate knowing how to code the solution in RegEx. True, RegEx does require learning some specialized code which is hard to remember if you aren’t a computer programmer who uses this stuff every day, but fortunately, there are lots of tools out there which can make this easier for you. The RegEx101 website linked to all of the searches in this tutorial is my favorite, but there are many other resources out there as well, not all of which require you to actually learn RegEx for yourself. In my next post, I plan to talk about some more user-friendly options, but I think it was important to first understand the underlying principles before moving on. If you don’t understand how tools like RegEx “see” text it is hard to understand what some of these other tools are doing. Hopefully, even if I haven’t convinced you to learn RegEx for yourself, you have gotten an idea of how it works and what kinds of things it can do.
List of posts in this series
- Free Your Mind, the Text Will Follow (Working With Text 1)
- RegEx 101 (Working With Text 2)
- Text-laundering (Working With Text 3)
- Lazy PowerPoint (Working With Text 4)
- Roll Your Own QDA (Working With Text 5)
- See here for instructions on using RegEx in Microsoft Word. ↩
- There are many great tutorials available online. Here’s one. ↩
P. Kerim Friedman is a professor in the Department of Ethnic Relations and Cultures at National Dong Hwa University in Taiwan. His research explores language revitalization efforts among indigenous Taiwanese, looking at the relationship between language ideology, indigeneity, and political economy. An ethnographic filmmaker, he co-produced the Jean Rouch award-winning documentary, ‘Please Don’t Beat Me, Sir!’ about a street theater troupe from one of India’s Denotified and Nomadic Tribes (DNTs).
2 Replies to “RegEx 101 (Working With Text 2)”
Another tip: regular expressions are great for making broken PDFs by government agencies and NGOs actually usable.
Just copy/paste a paragraph into a text editor like sublime and you can get rid of all the weird formatting and hard line breaks, or a table and convert it into tab-separated values to post into excel.
Got me through most of my polisci research projects in undergrad. 🙂
Yeah, I’m planning a post just on “cleaning” badly formatted text like that copied from PDFs. Building up to it slowly …